The biggest rating-comparison mistake is assuming one number means the same thing everywhere

the first source of mismatch is structural, not personal.
Players love conversion charts because they promise a shortcut. Unfortunately, the shortcut is often too confident. Chess.com, Lichess, and FIDE draw from different pools, use different systems or settings, and reflect different time-control habits. That means the same number can carry different meaning in each place.
This page owns the comparison intent. It is different from the broad Elo explainer, which teaches the concept, and different from the good-rating benchmark page, which focuses on milestones. Here the goal is to compare pools honestly.
That honesty matters because a fake exact conversion can produce the wrong expectations. It can make players underestimate over-the-board difficulty, misread online progress, or obsess over whether 50 points of difference means something huge when the pool itself is the bigger story.
A better comparison method uses ranges, same time controls, and a little humility about what rating numbers can and cannot prove across ecosystems.

the first source of mismatch is structural, not personal.
Why the numbers are different in the first place
Platforms are measuring overlapping but not identical competitive worlds. Different pools contain different habits, incentives, and levels of activity. Different rating systems or parameter choices shape how quickly numbers move, including expected score assumptions, K-factor style sensitivity, unrated-player handling, and rating change behavior.
That is also where many players misread their own results. That means a mismatch is not proof that one site is wrong. It usually means the environments are not identical enough to support exact equality.
A practical way to use this section is to translate the idea into decisions you can actually make during study and rating review, instead of treating the number as a mysterious label.
- Different pools contain different habits, incentives, and levels of activity.
- Different rating systems or parameter choices shape how quickly numbers move, including expected score assumptions and rating change behavior.
- That means a mismatch is not proof that one site is wrong.
- It usually means the environments are not identical enough to support exact equality.
Start here
Before comparing yourself, compare the systems and pools you are actually comparing.

mixing time controls is one of the fastest ways to create bad rating comparisons.
Time control matters more than most players think
A player can be disciplined and strong in rapid while still being weaker and more impulsive in blitz or bullet. Comparing blitz to rapid is already risky even on one platform. Comparing online blitz to over-the-board classical is even more misleading.
That is also where many players misread their own results. Strength changes with time pressure, habits, and practical decision quality. So the fairest comparison starts by matching the time control before anything else.
A practical way to use this section is to translate the idea into decisions you can actually make during study and rating review, instead of treating the number as a mysterious label.
- Comparing blitz to rapid is already risky even on one platform.
- Comparing online blitz to over-the-board classical is even more misleading.
- Strength changes with time pressure, habits, and practical decision quality.
- So the fairest comparison starts by matching the time control before anything else.
Use the cleanest comparison
Same platform, same time control, and a decent sample size will always beat flashy conversion charts.

exact conversion claims feel satisfying because they look precise, but they are often less truthful.
Broad rating ranges are better than exact conversion claims
Broad ranges respect pool differences, volatility, and sample-size noise far better than one-number translations. A range gives room for player style, activity, and time-control differences. It also reflects the fact that two players with the same label may arrive there through different strengths.
That is also where many players misread their own results. Range-based comparison is more useful for expectation setting than for bragging rights. That is why strong comparison pages should teach overlap, not fake certainty.
A practical way to use this section is to translate the idea into decisions you can actually make during study and rating review, instead of treating the number as a mysterious label.
- A range gives room for player style, activity, and time-control differences.
- It also reflects the fact that two players with the same label may arrive there through different strengths.
- Range-based comparison is more useful for expectation setting than for bragging rights.
- That is why strong comparison pages should teach overlap, not fake certainty.
Do not overfit the chart
If a converter promises one exact universal answer, treat it as a convenience tool, not as ground truth.
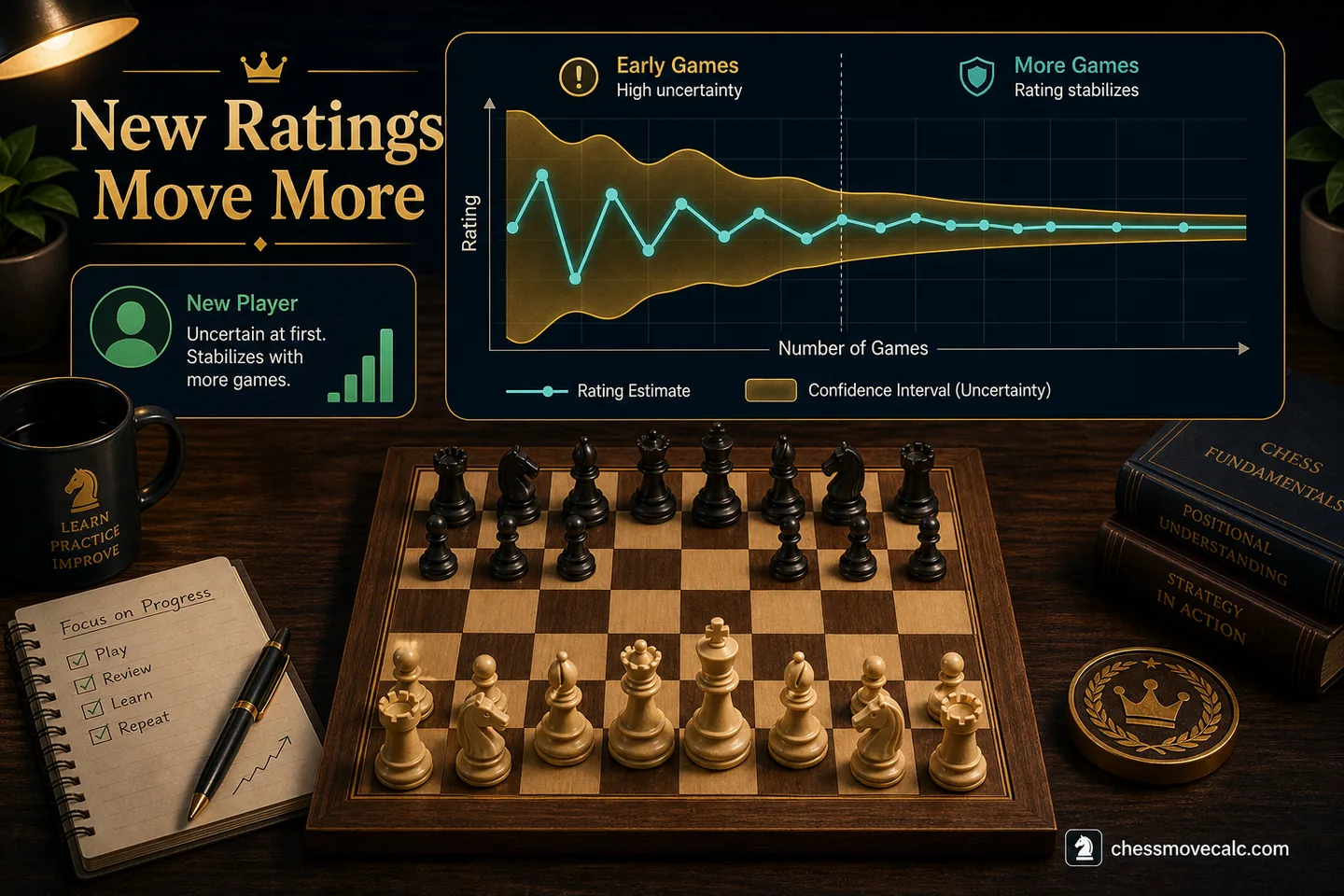
newer players are more volatile, which makes cross-pool comparison even noisier.
Why newer players see the biggest mismatch
A small sample and rapid improvement can create very different numbers across sites without any contradiction. Provisional or developing accounts move faster because the estimate is still settling. Players also learn differently across pools, which exaggerates early mismatches.
That is also where many players misread their own results. That means newer players should be especially cautious about reading deep meaning into exact comparisons. Stability matters, and stability usually arrives only after a larger game sample.
A practical way to use this section is to translate the idea into decisions you can actually make during study and rating review, instead of treating the number as a mysterious label.
- Provisional or developing accounts move faster because the estimate is still settling.
- Players also learn differently across pools, which exaggerates early mismatches.
- That means newer players should be especially cautious about reading deep meaning into exact comparisons.
- Stability matters, and stability usually arrives only after a larger game sample.
Be patient with the sample
The earlier your rating journey, the less useful exact cross-platform comparison becomes.

honest comparison is less glamorous, but it produces better decisions.
How to compare your strength more honestly
The goal is not to win an argument about numbers. The goal is to understand where you actually stand and what training fits next. Compare the same time control before you compare different ecosystems. Use broad ranges instead of point-perfect conversion claims.
That is also where many players misread their own results. Pair rating with game review, accuracy trends, and practical consistency. Let the comparison inform training goals rather than ego swings.
A practical way to use this section is to translate the idea into decisions you can actually make during study and rating review, instead of treating the number as a mysterious label.
- Compare the same time control before you compare different ecosystems.
- Use broad ranges instead of point-perfect conversion claims.
- Pair rating with game review, accuracy trends, and practical consistency.
- Let the comparison inform training goals rather than ego swings.
Better question
Ask where your rating is stable and what that says about your game, not only which pool makes you look highest.

estimates still help when they are used for planning rather than identity building.
When an estimate or converter is still useful
A good converter can frame rough expectations for a tournament, club match, or online-to-OTB transition. Use estimates to avoid unrealistic expectations before events. Use them to understand broad bands of likely difficulty, not precise promises.
That is also where many players misread their own results. Pair them with context from your own time-control history and recent games. The tool helps most when it informs decisions without pretending to remove uncertainty.
A practical way to use this section is to translate the idea into decisions you can actually make during study and rating review, instead of treating the number as a mysterious label.
- Use estimates to avoid unrealistic expectations before events.
- Use them to understand broad bands of likely difficulty, not precise promises.
- Pair them with context from your own time-control history and recent games.
- The tool helps most when it informs decisions without pretending to remove uncertainty.
Healthy use case
A converter is strongest as a planning aid, not as a final statement about who you are as a player.

The best rating comparisons are cautious, contextual, and useful.
Comparison habits that protect you from fake certainty
Cross-platform comparison becomes more honest when you treat it as a range-and-context exercise instead of a one-number conversion puzzle. The same player can legitimately present different numbers without any contradiction. Time control, pool behavior, and update logic all influence what the rating is really saying.
The best comparison starts with the same time control and a stable sample size. The next best step is broad range thinking instead of exact equality claims.
A stronger habit is to ask what decision this concept should improve the very next time it appears. When used this way, converters become planning tools instead of mythology machines. That protects both your expectations and your training decisions.
That bridge is often the missing ingredient between reading an article once and truly keeping the lesson when the position becomes real.
- The same player can legitimately present different numbers without any contradiction.
- Time control, pool behavior, and update logic all influence what the rating is really saying.
- The best comparison starts with the same time control and a stable sample size.
- The next best step is broad range thinking instead of exact equality claims.
- When used this way, converters become planning tools instead of mythology machines.
- That protects both your expectations and your training decisions.
Practical takeaway
When used this way, converters become planning tools instead of mythology machines. That protects both your expectations and your training decisions.

Chess.com vs Lichess vs FIDE Ratings FAQs
Why is my Lichess rating higher than my Chess.com rating?
Different pools, different settings, and different time-control habits can all produce that pattern.
Can I convert my online rating exactly to FIDE?
Not exactly. Broad ranges are more honest than exact one-number conversions.
Does time control really matter that much?
Yes. A player can have meaningfully different strength profiles across bullet, blitz, rapid, and classical.
Why do newer players see bigger mismatches?
Their ratings are often more volatile and less settled across pools.
Is a converter still useful at all?
Yes, if you use it for rough expectation setting instead of treating it as perfect truth.
What is the fairest way to compare ratings?
Match the time control, use a decent sample size, and compare ranges rather than exact points.
Compare your rating pools with realistic expectations
Use the calculator and the benchmark guides together so your comparison leads to better training decisions.
